The dream of every artist is to go viral on Spotify. Hacking the Spotify algorithm comes with global exposure, the influx of deals from labels, and of course, plenty of money.
It is not enough to record great music; you must also understand how the Spotify algorithm works. In this guide, we will explain how you can unlock the potential of Spotify and expose the way the algorithm works through natural language processing, content-based filtering, and collaborative filtering.
Spotify triggered a paradigm shift in the music industry in 2008 with music streaming. Its emergence made CDs and DVDs things of the past. For a small monthly fee per user, the Swedish company made millions of records available to listeners.
Even though Spotify started earlier than most digital streaming platforms, it is not safe from the wrath of competition. The streaming giant is contesting with the likes of Apple Music and Amazon (Amazon Music), and Google (YouTube Music), hence it is left with two options — dominate or face the fate of obsolete streaming platforms like Soundcloud and Napster. According to Statista, Spotify has 188 million paying subscribers globally. Please note that its total number of users (both free and premium) exceeds 365 million).
Although Spotify is on its winning streak, it is losing market share to Apple Music, especially in the States. The only way out for Spotify is to solidify its influence among music listeners and artists. That feat can be attained with the help of smart algorithms and machine learning programs.
Convincing users to become premium consumers becomes a lot easier when the user experience on the platform is top-notch. People just want an unlimited good music experience and they would not mind paying for it.
So far, so good; Spotify has been doing good despite the pressure from competitors and scandals that have rocked its very foundation. How did they come this far? Your guess is as good as mine; by garnering reliable data and actively tweaking their algorithm. So let’s dive deeper into the physiology of Spotify’s popular algorithm.
Spotify Home Screen
Spotify Home Screen is like the maitre d’hotel that gave you a warm welcome when you lodged at a guest house during your last vacation to Italy.
Right off the bat, Spotify greets its visitors with customized playlists and recommendations. Intrigued users are presented with a variety of recommended playlists. Famous examples of recommended playlists are Release Radar, Discover Weekly, your mixtapes, B Slide, etc.
The Other sections menu aka shelves features Recently Played, Recommended for today, or Jump Back In.
The Spotify home screen is designed to suck listeners back into the streaming app. If there is one thing Spotify hates, it is users exiting their app. The AI responsible for creating and curating the home screen is dubbed BaRT (meaning Bandits for Recommendations as

Treatments). We will give you a breakdown of BaRT as we proceed.
If you are logged into Spotify as a user, you will find sections like “Recommended songs” (automatic playlist continuations), and you “might also like” placed side by side with the recommended playlists mentioned earlier. Also, these sections are placed under every playlist and album. The idea is that no user screen is the same and every user has a customized Spotify screen.
All backend designers will tell you that you need data to run an interactive user interface, hence Spotify’s algorithm is only as powerful as the data its users feed it when they click the “allow Spotify to track…” pop-up.
The data is needed to dish out music to users and fine-tune the song predictions whether the user is on the Spotify app or listening to music in the background. How does Spotify get its data and what are its sources? Let’s find out in the next section.
Data
Like all big data collectors, Spotify needs the user’s approval to kick-off. Most Spotify users are cool with being tracked because they enjoy the superb user experience, perfect recommendations, and end-of-the-year stats provided by Spotify.

Spotify tracks everything from the time spent on the platforms to the songs interacted with the most.
Spotify wrapped became a thing in 2020. There’s a really good chance you have come across a screenshot of Spotify Wrapped from a random Twitter user. The feature offers users the breakdown of the duration and the genres they listened to the most.
Users post their SPotify Wrapped to boast about the uniqueness of their music taste. The information contained in Spotify’s “year in review” report includes the listening time, genre, favorite podcasts, favorite artists, and newcomers.
It is not just the users who provide Spotify with data, the artists are not exempted. Without lifting a finger, Spotify is showered with details such as song descriptions, song names, genre, song files, lyrics, and images. The more data Spotify collects from you as an artist, the higher your chance of getting playlisted on algorithmic playlists and recommended to its users.
When consumers consent to share their data with Spotify, they give the streaming giant the access to their skipped songs, listening history, number of times a song is repeated, social interactions (when they share music covers to social media sites like Instagram and Twitter), and playlists stored.
While getting internal data from artists and users, Spotify also gets external data from its blog posts or articles about music.
Spotify Acquisitions
In the tech space, there are two ways you can own an innovation. You can either sponsor research into the field and build for years or just acquire people who have created what you want. An acquisition is like a larger whale suckin-up smaller fishes. For just 100 million dollars, Spotify bought Echonest in 2014.
Echonest is a music intelligence and data platform that had over 1 billard of data on songs and artists when it was acquired by Spotify. Its strategy of amassing data according to its founder (Brian Whitman) is filtering over 10 million websites in the music space to determine what’s popping and what’s not.
Another acquisition that strengthened Spotify’s leverage in the music market is the acquisition of Seed Scientific, a data science and analytics consultancy.
Two years after the deal, Spotify also acquired Sonalytic, an audio detection company.

Audio detection technology helps identify a song even if you have no metadata about the song. If you have used Shazam before, you would clearly understand the concept of audio detection.
There are two major ways Spotify benefits from audio detection. Firstly, it helps them tackle the issue of copyright violations and avoid being sued by artists and labels. Secondly, it uses audio detection to fortify the customization in playlists and songs so they can “match songs with compositions and…improve its publishing data system”. These three purchases are part of what makes Spotify better than its rivals.
Even though the amount spent for the deal to come to fruition was not disclosed, the deal must have cost Spotify millions of dollars at least. Why did Spotify bet on Sonalytic?
Recommender System
Every giant tech service has a recommender system that predicts what the user wants and recommends it to them. Recommender systems determine what movie a user wants to see next (Netflix), what keyword the consumer may be interested in (Google), and the type of music a Kanye fan would appreciate when discovered (Spotify). Now that I think about it, the recommender system pretty much rules the internet. It is on every app and site you turn to.
The recommender system is reliant on consumer behavior and data inputted directly when filling forms or bio. People are comfortable with the recommender system doing the hard work for them. According to the Spotify Research Team, “users are overwhelmed by the choice of what to watch, buy, read, and listen to online”, making recommender systems essential in the decision-making process. The work of the recommender system is simply to suggest music to Spotify users.
At the beginning of the article, we stated that the Spotify algorithm works via collaborative filtering, natural language processing, and a content-based recommender system. Let’s discuss the three methods in detail.
- Collaborative-filtering: A jazz listener barely changes genre overnight and many people have favorite musicians whom they would listen to for life. Collaborative filtering works based on the logic that users would repeat similar decisions they’ve made in the past and love the type of music they’ve always listened to.
- Content-based: Black Americans love hip hop because it was created by them and features a good part of their history. In simple terms, they love hip hop because it is relatable. Content-based recommender systems predict content based on the data inputted by the user, for instance, age, gender, territory, and preferred genre.
- Hybrid: Hybrid recommender systems use both methods — that is content-based and collaborative filtering — to predict songs to listeners. Once you understand the three above-mentioned systems, it will be easy to comprehend the Spotify BaRT algorithm. Let’s go.
What is BaRT?
We briefly explained what BaRT stands for in the early part of this guide. The BaRT algorithm can switch between two modes: exploration and exploitation.
The exploitation mode helps users find music based on what they already like while the exploration mode helps them find new music without considering their music consumption history.
The data considered in exploitation mode include the skips, liked songs, and repeated songs. The exploration mode relies on data from the trending music to what other users enjoy, as Spotify users don’t just want to be fed with what they already love, they also want to explore new music on the platform.
Primarily, recommender systems function in exploitation mode using collaborative filtering. It is the bees knees when the users provide it with sufficient data.

However, on the flipside, exploitation mode flops when there is no data for the algorithm to act on, meaning the user has not interacted enough with the Spotify app. The exploitation mode is always at the mercy of the user.
When the exploitation mode fails, the exploration mode comes into action. The designers of the BaRT algorithm anticipated such situations. Exploration mode does not require data from the user to function. In fact, it blossoms in uncertainty.
According to a research titled — Explore, Exploit, and Explain: Personalising Explainable Recommendations with Bandits by James McInerney, Benjamin Lacker, Samantha Hansen, Karl Higley, Hugues Bouchard, Alois Gruson, and Rishabh Mehrotra – Exploration recommends content with uncertain predicted user engagement for the purpose of gathering more information. The importance of exploration has been recognized in recent years, particularly in settings with new users, new items, non-stationary preferences, and attributes.
Simply put, the algorithm gives a new song a chance to shine even though it has not garnered enough user data about it. When the BaRT algorithm gives a new song exposure, it monitors and records how users interacted with the record.
When users listen to a song for less than 30 seconds, it hurts their chances of getting more exposure. On the other hand, when users listen for more than 30 seconds and interact with the song further via playlisting, liking or saving, the song gets more exposure.
The BaRT algorithm considers the negative and positive recommendations before choosing what songs to recommend to more users.
The exploration mode is useful when there is low certainty on the relevance of a record while the reverse is true for the exploitation mode. Yes, the BaRT model can make mistakes but the beauty of the algorithm is that it learns from its mistakes and predicts better next time. It gauges consumer satisfaction using click-through rates and positive feedback.

Through reinforcement learning, BaRT is able to log, learn and adjust using its experience with millions of Spotify users. To provide optimal satisfaction and correctly recommend songs to users, the BaRT model utilizes a multi-armed bandit (which is programmed to initiate a specific action ‘A’ in anticipation of the best reward ‘R’. Therefore, future action ‘A’ is reliant on former actions and rewards.
A Multi-armed Bandit (aka MAB) is tasked to pick actions that optimize the overall sum of rewards. The first type of MAB did not have an eye for the context of the task such as device, playlist, time of the day, user features among others. To better serve the listeners, the Spotify team came up with a better version which is also known as the contextual multi-armed bandit. This version collects and considers contextual data before picking the appropriate action.
Four determinants are responsible for the success or failure of a contextual MAB,
namely the context, the training procedure, the reward model, and the exploitation-exploration policy. The report quoted earlier offers a formula for getting any of the three parameters that are contained within the reward mode. The three parameters are an item j (the record), an explanation e (why the song was chosen), and the context x. The formula below houses the three parameters.
![]()
θ refers to the coefficients of the logistic regression and 1_i denotes a one-hot vector of zeros with a single 1 at index.
Currently, the reward function influences the action. In a specific context x the user u initiates the maximal action using the equation below
![]()
The authors in the report we quoted earlier used the epsilon greedy for the exploration approach. According to them, “[This “gives equal probability mass to all non-optimal items in the validity set f (e,x) and (1−ε) additional mass to the optimal action (j∗,e∗).” [2] The policy is set to “either exploit or explore the item and explanation simultaneously”.
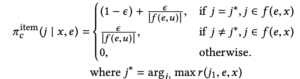
The procedure by which the algorithm enlightens itself is not out of the ordinary as BaRT educates itself periodically in batch mode. The problem that arises when the algorithm encounters a new artist with no prior songs to learn from is called the cold start problem. Collaborative filtering is not the best method for new and relatively unknown songs.
How Spotify solves the cold start problem
When there is no historical data to learn from, the major source of data at the algorithm’s disposal is the record itself. While this process of evaluation is quite complex and requires thorough computer activity, it is necessary to solve the cold start problem and give the algorithm an edge.
Regarding how records are analyzed, a then-employee of Spotify named Sander Dieleman gave a detailed explanation in a 2014 blog article. According to Sander, the model has four convolutional layers and three dense layers. Instead of inputting the raw audio files, the machine learning model adopts spectrograms which are just representations of the audio track. Every song analyzed through this process is converted to Mel-spectrograms.

The Mel-spectrogram of a track is unique to it, making it a valid way of interpreting audio files. It is a time-frequency graph plot of audio. The concept behind the Mel scale is to imitate the human listening response.
There is a good likelihood that the current Spotify algorithm has the Spotify Dieleman prototype, thereby rendering his model obsolete. However, if you are interested in his explanations, you can check out this report.
Natural Language Processing and Music Intelligence
The acquisitions of Echonest places Spotify on par with its competitors, data-wise. The music intelligence platform uses web crawling and Natural Language Processing to track and store information from over 10 million websites. With the aid of NLP, Spotify can keep up with trends, discussions, and people’s predilections in the music industry. The NLP system can also measure the relevance of certain musical keywords.
Final Thoughts: How to “Exploit” the BaRT algorithm
It’s pretty simple. Feed the Spotify algorithm with data. The first way to feed the algorithm with data is to submit your music for playlisting prior to the release date.
When pitching your song, fill out the form and send links to blog posts mentioning your new project (as it will help the NLP system).
Also, ensure that you push the music on the first week of release so that the algorithm can get information from your listeners and push the record to similar listeners.
Please do not add your song to unrelated playlists because the algorithm will punish your record when it gets negative feedback from uninterested listeners.
